Accelerate your visual product with elite Computer Vision engineering.
We design, optimize, and deploy high-performance visual intelligence systems. From custom deep learning model training to sub-millisecond edge inference and multi-stream analytics, we build robust vision systems that stand the test of real-world production.

ENGINEERED WITH HIGH-PERFORMANCE VISUAL AI FRAMEWORKS
Our visual AI capabilities
We engineer high-performance computer vision systems tailored for visual inspection, security, robotics, agriculture, and defense. From raw pixels to real-time production inference.
Custom Model Training & Fine-Tuning
We train, evaluate, and deploy high-accuracy custom deep learning models optimized for your unique visual datasets. From YOLOv8/v10 object detection to Segment Anything (SAM) zero-shot segmentation.
Key Deliverables
- ✦Custom Object Detection (YOLO, Faster R-CNN)
- ✦Semantic & Instance Segmentation (SAM, Mask R-CNN)
- ✦Custom Visual Classification & Feature Vectors
- ✦Transfer Learning & Fine-Tuning Pipelines
Real-Time Video Analytics Pipelines
High-throughput live stream ingestion and event detection systems. We engineer multi-camera processing engines designed to count objects, track movement vectors, identify anomalies, and trigger instant system notifications.
Key Deliverables
- ✦Multi-Stream RTSP / WebRTC Video Ingestion
- ✦Object Tracking & Directional Counting (ByteTrack)
- ✦Virtual Boundary & Intrusion Detection
- ✦Density Estimation & Heatmap Generation
Model Optimization & Edge Deployments
Unlock maximum hardware capabilities with custom inference acceleration. We compile and optimize deep learning models for sub-millisecond speeds on specialized edge devices, reducing cloud costs and latency.
Key Deliverables
- ✦Model Quantization & Pruning (FP16, INT8)
- ✦TensorRT & ONNX Runtime Compilations
- ✦NVIDIA Jetson & Embedded Hardware Deployment
- ✦High-Concurrency Cloud GPU Scaling
Dataset Annotation & Curation Pipelines
High-quality dataset curation is the absolute foundation of successful AI. We construct robust visual dataset pipelines, implement automated pre-labeling routines, and manage precise manual annotation QA.
Key Deliverables
- ✦Automated Pre-Labeling & Data Augmentation
- ✦Dataset Curation, Deduplication, & QA Auditing
- ✦Exporting to COCO, YOLO, & Pascal VOC Formats
- ✦Synthetic Image Generation & Augmentations
Proven Client Deliveries
Explore a selection of computer vision applications, machine learning systems, and full-stack solutions built for global clients.
Nighttime Headlight and Road Glare Detection using Computer Vision
Built a computer vision system that detects and segments vehicle headlights and road surface reflections in nighttime driving conditions. Unlike standard approaches that only detect headlights, the system also handles glare reflections on wet road surfaces, making it more robust for real-world night driving scenarios.
Engage-AI — Multimodal Student Engagement Detection System
Built an AI-powered classroom engagement monitoring system using computer vision. The system detects students in lecture videos using YOLO, then runs parallel emotion and action detection engines to compute real-time engagement metrics. Results are displayed on a role-based dashboard for teachers and HODs, with export functionality. Built with Python, FastAPI, and React.
ParkAI — Smart Parking Occupancy Monitor & Analytics Pipeline
Built an AI-powered smart parking occupancy monitoring system using computer vision. The system detects vehicles in CCTV or drone footage using YOLOv8, then runs a custom polygon mask overlap checking algorithm to dynamically identify occupied versus vacant parking slots. Real-time telemetry metrics are computed frame-by-frame and overlaid on the output video feed, tracking total vehicles and occupancy rates. Built with Python, OpenCV, YOLOv8, and PyTorch
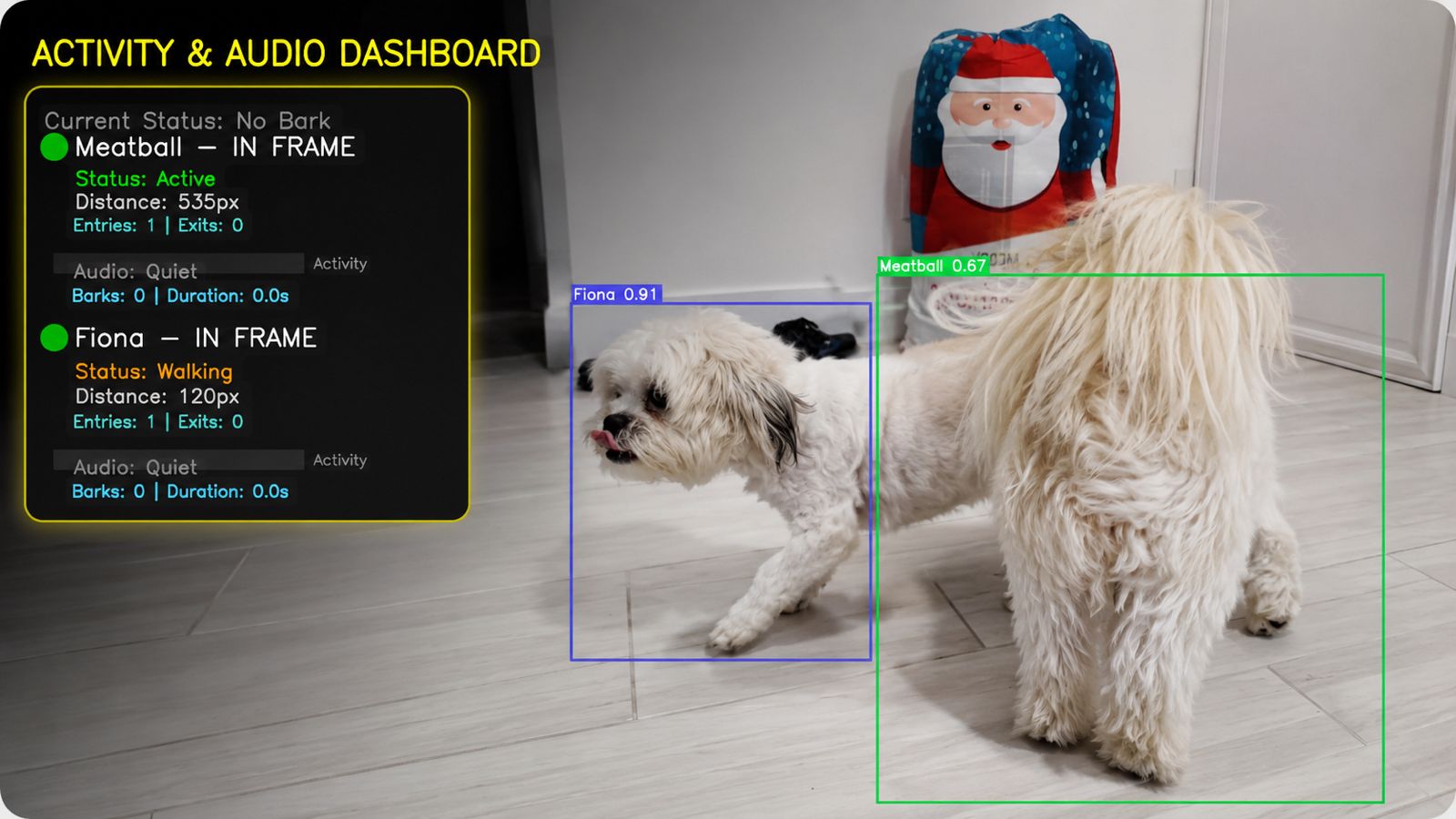
PupLink — Real-Time Multi-Dog Detection & Behavior Analysis System
Real-time CV system detecting multiple dogs simultaneously, classifying individual behaviors, and ranking each by activity level in live video. Built with YOLOv8 trained on a custom-annotated dataset. Optimized inference pipeline for low-latency video processing on Raspberry Pi edge hardware. Live streaming via WebRTC with FastAPI backend serving real-time detection results. Pipeline: data annotation → YOLOv8 fine-tuning → evaluation → edge deployment.
Our visual AI stack
PyTorch & Custom Deep Learning
Our primary framework for designing custom neural networks, fine-tuning pre-trained backbones, and building state-of-the-art vision models.
OpenCV & GStreamer Pipelines
Efficient live frame ingestion, matrix transformations, hardware-accelerated RTSP streams, and high-throughput video processing pipelines.
TensorRT & ONNX Compiler
Compiling models to dedicated GPU structures, executing layer fusion, and quantizing weights to FP16/INT8 for sub-millisecond execution.
NVIDIA CUDA & Triton Server
Direct GPU computing to accelerate heavy tensor operations and scaling concurrent inference pipelines across cloud GPU servers.
NVIDIA Jetson Edge Devices
Deploying highly optimized deep learning models directly on low-power Orin modules for zero-network embedded applications.
Dataset Curation & CVAT Tools
Implementing automated data-labeling loops, cleaning dataset noise, and applying targeted data augmentations to maximize model recall.
Common questions
Let's build
something great
Ready to accelerate your visual AI product? Contact our engineering team to schedule a technical discovery call.